![]()
Generando Procedimientos Almacenados de manera automática
Fecha: 05/Ago/2005 (04-08-05)
|
Hola, mi nombre es Martín Luchessi. Soy de Rosario, Argentina y es la primera vez que escribo (o al menos, intento escribir) un artículo sobre informática, asi que por favor, ténganme paciencia. :P
La idea de este artículo es explicar, al menos desde mi experiencia, el uso de las vistas de sistema y funciones de SQL Server, para realizar un script que genere código SQL para crear un procedimiento almacenado (desde ahora en adelante, PA) que actualice, modifique y elimine registros de una tabla dada de acuerdo a la clave de la misma.
Si bien con SQL Server 2000 podemos generar 3 PAs que hagan las 3 consultas por separado, la idea es que este script genere UN solo PA y que realice la acción correspondiente de acuerdo a un parámetro del PA.
Este script generará un código que se escribirá en el panel de resultados de SQL Server, el cual nosotros copiaremos luego para correrlo en una nueva consulta.
Es decir, la idea es que el código generado sea algo asi:
CREATE PROCEDURE <NOMBRE_DEL_PA>
(
@p_parametro1 TIPO_DATO,
@p_parametro2 TIPO_DATO,
…
@p_tipo_accion CHAR(1)
)
AS
Si @tipo_accion = ‘A’ –-acción ACTUALIZAR O INSERTAR
si no existe un registro en la tabla indicada para la clave de la misma
Ejecuto una consulta INSERT sobre la tabla
si existe el registro
Ejecuto una consulta UPDATE sobre la tabla
END
IF @tipo_accion = “E” –acción ELIMINAR
Borro los registros de la tabla.
Devuelvo cantidad de registros actualizados por la consulta
Vale la pena aclarar, que al momento de borrar registros, el script no controla (al menos esta versión no lo hace) que existan tablas relacionadas con la tabla de la cual se desea borrar registros. Es decir, si quiero borrar una persona y esta tiene números de teléfonos relacionados, si existe una restricción de clave foránea armada para la tabla de personas, con aquella que guarda los números de teléfonos, el motor de base de datos generará una excepción y no permitirá efectuar la consulta. De la misma manera, tampoco controla que, al momento de insertar un nuevo registro en la tabla, se esté ingresando datos que no existan en tablas relacionadas con ésta.
Bueno, basta ya de explicaciones y pongámonos manos a la obra.
DECLARACIÓN DE LAS VARIABLES DE ENTRADA.
En primer lugar, necesitaremos 2 variables importantes para este script. Una que contendrá el nombre de la tabla sobre la que generaremos el PA y otra que contendrá el nombre del PA. Ésta variable en realidad puede ser obviada, ya que podemos dejar que el script se encargue de nombrar el PA. En mi caso yo elegí que si esta variable viene vacía el PA se llame “PA_ABM_NOMBRE_TABLA”, pero es algo que fácilmente pueden cambiar si no les gusta. Ambas variables fueron declaradas como SYSNAME, ya que éste es el tipo de datos suministrado por el sistema y definido por el usuario que es funcionalmente equivalente a nvarchar(128) y que se utiliza para hacer referencia a nombres de objetos de bases de datos.
A continuación escribimos dos líneas que nos permitirán asignarle valor a estas variables. Los valores van escritos entre comillas simples por ser SYSNAME un tipo de dato de texto.
DECLARE @P_NOMBRE_TABLA SYSNAME
DECLARE @P_NOMBRE_PA SYSNAME
set @P_NOMBRE_TABLA = 'aquí va el nombre de la tabla'
set @P_NOMBRE_PA = 'aquí va el nombre del PA si quieren asignarle uno'
Esta sección es la única parte del código que tendremos que modificar, cuando queramos generar un PA para una tabla.
DECLARACIÓN DE VARIABLES AUXILIARES
Las siguientes son variables auxiliares que nos ayudarán a mantener el texto que deberá escribir el script en el panel de resultados del Analizador de Consultas de SQL Server 2000.
DECLARE @SQL_CABECERA VARCHAR(8000)
DECLARE @dato VARCHAR(8000)
DECLARE @SQL_WHERE VARCHAR(8000)
DECLARE @SQL_UPDATE VARCHAR(8000)
DECLARE @SQL_INSERT VARCHAR(8000)
DECLARE @SQL_VALUES VARCHAR(8000)
DECLARE @SQL_DELETE VARCHAR(8000)
La variable @SQL_CABECERA la utilizaremos para guardar la cabecera del PA. Es decir, toda la sección que comprende la verificación de que el PA exista en la base de datos, la eliminación y posterior creación del PA con sus parámetros.
Las restantes variables declaradas arriba se utilizarán para armar cada consulta.
Ahora bién. ¿Cómo sabemos que tabla hay que actualizar y bajo qué condición? ¿Cómo sabemos cuales columnas son clave de la tabla y cual no? ¿Qué tipo de dato tiene cada columna de la tabla? Todos estos datos son necesarios para actualizar una tabla, o mejor dicho, sus datos.
Para esto, vamos a necesitar, una variable de tipo TABLE, que me permita dejar registrado todas las características de la tabla sobre la que se quiere operar. Y además, el órden en que se encuentran las columnas, para luego poder respetar los índices de la tabla.
DECLARE @tabla TABLE(orden smallint, columna SYSNAME, pk BIT, parametro varchar(25), tipo_dato varchar(25), largo smallint, decimales smallint)
La columna columna, contendrá el nombre de las columnas de la tabla.
La columna PK, nos indicará si la columna de la tabla es Primary Key o no.
La columna parámetro, nos servirá para saber a que parámetro del PA corresponde esta columna.
La columna tipo_dato, largo y decimales dejarán registrado que tipo de dato tiene la columna de la tabla, el largo del tipo de dato y la precisión del mismo.
También necesitaremos declarar variables para las columnas, para utilizarlas a la hora de recorrer la VARIABLE @tabla.
DECLARE @orden SMALLINT
DECLARE @largo SMALLINT
DECLARE @decimales SMALLINT
DECLARE @pk BIT
DECLARE @parametro VARCHAR(25)
DECLARE @columna SYSNAME
Por último,esta variable @update, sirve como bandera para controlar que si la tabla es una tabla TODO-CLAVE, es decir, que todas las columnas de la tabla son clave primaria, no será necesario hacer un update de la misma. Por lo tanto, tomará valor 0 (cero) cuando no sea necesario y 1 (uno) cuando si lo sea.
DECLARE @update BIT
VALIDANDO LA EXISTENCIA DE LA TABLA
Antes de empezar a generar el código, sería interesante que el script controle que la tabla sobre la cual se quiere generar el PA exista.
Si el nombre de la tabla está vacío, sería interesante imprimir un cartel insitando al programador, o usuario del script , a que escriba un nombre de una tabla, sino el script no tendría sentido.
IF LEN(@p_nombre_tabla)=0
begin
PRINT 'ESTAS PENSANDO EN LO QUE HACES? Y EL NOMBRE DE LA TABLA? '
PRINT 'ADIVINO NO SOY!'
RETURN
end
Del mismo modo, un nombre de tabla inválido tendría el mismo efecto y podemos generar un mensaje de error de la base de datos, haciendo una consulta sobre la tabla inexistente, para obviarnos el poner un mensaje nosotros,.
IF OBJECT_ID(@p_nombre_tabla) IS NULL
begin
--PRINT 'LA TABLA <' + @p_nombre_tabla + '> NO EXISTE COMO UN OBJETO'
SET @p_nombre_tabla='SELECT 1 FROM ' + @p_nombre_tabla
exec(@p_nombre_tabla)
return
end
La función Object_ID(objeto) devolverá null si la tabla no se encuentra en la base de datos y el ID de la tabla, en caso contrario.
RECOLECTANDO DATOS SOBRE LA TABLA
Para armar este script vamos a necesitar distinguir las distintas partes del PA que queremos que arme. Para mi entender, el PA consta de 4 partes:
· CABECERA
· CONSULTA INSERT
· CONSTULTA UPDATE
· CONSULTA DELETE
En la cabecera, cómo dije anteriormente, vamos a escribir la creación del PA, con sus parámetros y los tipos de datos de los mismos. Además, vamos a agregarle valores por defecto a estos, para asi lograr que se puedan obviar ciertos parámetros cuando se quiera ejecutar el PA desde alguna aplicación. Por ejemplo, cuando se quiera hacer un DELETE los únicos parámetros que tendremos que pasarle serían aquellos que son clave de la tabla y el parámetro “@p_accion = ‘E’”.
En la consulta INSERT, no tendremos demasiados problemas. Sólo necesitamos los nombres de las columnas y sus valores.
En cambio en las consultas UPDATE y DELETE necesitaremos armar el WHERE de la consulta, y es aquí donde viene el pequeño problema ya que necesitaremos saber cuáles columnas son PRIMARY KEY y cuales no.
Aquí haremos uso de la variable @Tabla que hemos declarado al comienzo de nuestro script para poder guardar toda la información que necesitemos sobre la tabla que estamos trabajando y así no hacer una consulta a las tablas de sistema cada vez que lo requiramos.
Para buscar información sobre las tablas haremos uso de las VISTAS DE ESQUEMA DE INFORMACIÓN de SQL Server 2000.
Estas vistas proporcionan una vista interna e independiente de las tablas del sistema de los metadatos de SQL Server. Las vistas de esquema de información permiten que las aplicaciones funcionen correctamente aunque se hayan realizado cambios significativos en las tablas del sistema. Las vistas de esquema de información que contiene SQL Server cumplen la definición del estándar SQL-92 para INFORMATION_SCHEMA.
Estas vistas se definen en un esquema especial llamado INFORMATION_SCHEMA, contenido en cada base de datos. Cada vista de INFORMATION_SCHEMA contiene metadatos para todos los objetos de datos almacenados en esa base de datos en particular. Esta tabla describe las relaciones existentes entre los nombres de SQL Server y los nombres estándar de SQL-92.
Vamos a utilizar las siguientes vistas:
· COLUMNS
Contiene una fila por cada columna a la que puede tener acceso el usuario actual en la base de datos actual.
· TABLE_CONSTRAINTS
Contiene una fila por cada restricción de tabla de la base de datos actual. Esta vista de esquema de información devuelve información acerca de los objetos sobre los que el usuario actual tiene permisos.
· KEY_COLUMN_USAGE
Contiene una fila por cada columna, de la base de datos actual, que está restringida como clave. Esta vista de esquema de información devuelve información acerca de los objetos sobre los que el usuario actual tiene permisos.
De la vista COLUMNS nos interesa buscar el nombre de cada columna de la tabla (COLUMN_NAME), el tipo de dato de cada columna (DATA_TYPE), el tamaño máximo de caracteres (CHARACTER_MAXIMUM_LENGTH) en caso de tipos de dato de texto, o la precisión (NUMERIC_PRESICION) en caso de tipos de datos numéricos (en caso de datos con decimales, necesitaremos saber cuántos decimales tiene con (NUMERIC_SCALE)), y el número identificador de columna (ORDINAL_POSITION).
Las vistas KEY_COLUMN_USAGE y TABLE_CONSTRAINTS las vamos a usar para ver que columnas de la tabla son PRIMARY KEY haciendo una consulta y relacionando columnas entre las vistas.
Así, cada dato que seleccionemos de estas vistas, lo insertaremos en la variable @tabla, de la siguiente manera:
insert into @tabla
select
COLS.ORDINAL_POSITION,
COLS.COLUMN_NAME,
convert(bit,(
select count(*)
from
INFORMATION_SCHEMA.TABLE_CONSTRAINTS as CONST
JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE as COL ON
CONST.TABLE_SCHEMA = COL.TABLE_SCHEMA AND
CONST.TABLE_NAME = COL.TABLE_NAME AND
CONST.CONSTRAINT_NAME = COL.CONSTRAINT_NAME
where
CONST.CONSTRAINT_TYPE = 'PRIMARY KEY' AND
CONST.CONSTRAINT_SCHEMA = 'dbo' AND
COL.TABLE_NAME = COLS.TABLE_NAME AND
COL.COLUMN_NAME = COLS.COLUMN_NAME
)),
'@p_' + COLS.COLUMN_NAME,
UPPER(COLS.DATA_TYPE),
ISNULL(COLS.CHARACTER_MAXIMUM_LENGTH,NUMERIC_PRECISION),
isnull(cols.numeric_scale,0)
from
INFORMATION_SCHEMA. COLUMNS COLS WITH (NOLOCK)
where
COLS.TABLE_NAME = @P_NOMBRE_TABLA
order by
cols.ordinal_position
1
2
3
4
5
6
7
8
Como podemos observar, en las líneas 1 y 2, estamos usando las columnas ORDINAL_POSITION y COLUMN_NAME para guardarlas en las columnas “orden” y “columna” de la tabla @tabla.
En la línea 3 nos vamos a detener un poco. Más arriba en este artículo, habíamos dicho que necesitábamos saber qué columnas de la tabla eran clave primaria para poder luego armar el WHERE de las consultas UPDATE y DELETE. Aquí se está realizando una subconsulta para contar todas las columnas cuyo tipo de constraint sea “PRIMARY KEY” de la tabla @P_NOMBRE_TABLA, relacionando las vistas TABLE_CONSTRAINTS y KEY_COLUMN_USAGE por medio de sus columnas TABLE_SCHEMA, CONSTRAINT_NAME y TABLE_NAME, para ver cuales son las restricciones de @P_NOMBRE_TABLA. Como sólo nos interesa la restricción PRIMARY KEY, filtramos por la columna CONSTRAINT_TYPE de la vista TABLA_CONSTRAINTS.
A continuación, convertimos el valor que devuelve la subconsulta a Bit, asi podremos guardar en la columna PK de @tabla , un 1 si el COUNT es > 0, y 0 en caso contrario.
En el renglón marcado con el número 4 estamos guardando el valor para la columna @parametro de la variable @tabla, ya con el agregado del prefijo “@p_”, que nos indicará cuál es el parámetro del PA que le corresponde a cada columna.
En la linea 5, vamos a guardar el tipo de dato de la columna, y en las líneas 6 y 7 obtendremos el largo del tipo de dato y la precisión. Si CHARACTER_MAXIMUM_LENGHT es NULL entonces guardermos NUMERIC_PRESICION, ya que estaríamos en presencia de un tipo de dato numérico. Si NUMERIC_SCALE es NULL entonces guardaremos 0 ya que estaríamos en presencia de datos enteros, texto. Para los tipos de dato DATETIME no nos interesa tener mucho detalle en este caso.
En las líneas 7 y 8 solamente le indicamos a la consulta en que tabla queremos que busque información y ordenamos por ORDINAL_POSITION para que busque en el orden de las columnas de la tabla.
Veamos todo esto en un ejemplo práctico.
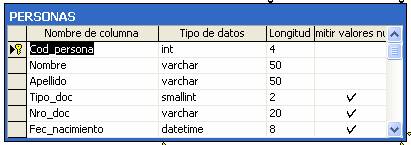
Ejemplo: PA sobre la tabla PERSONAS.
Supongamos una tabla PERSONAS con los siguientes atributos.
Si hacemos una consulta sobre la variable @tabla, luego de recabar los datos, daría un resultado como este:
orden
columna
pk
parametro
tipo_dato
largo
Decimales
1
Cod_persona
1
@p_Cod_persona
INT
10
0
2
Nombre
0
@p_Nombre
VARCHAR
50
0
3
Apellido
0
@p_Apellido
VARCHAR
50
0
4
Tipo_doc
0
@p_Tipo_doc
SMALLINT
5
0
5
Nro_doc
0
@p_Nro_doc
VARCHAR
20
0
6
Fec_nacimiento
0
@p_Fec_nacimiento
DATETIME
23
3
Cómo podemos observar, la columna Cod_persona, tiene un 1 en PK, es decir que es clave primaria. El parámetro que le corresponderá en el PA se llamará @p_Cod_persona, es de tipo INT con un largo de 10 y 0 decimales, lo cual es correcto.
Ahora, vamos a acomodar la columna tipo_dato de @tabla para que contenga el podamos tener el tamaño máximo de caracteres, o la presición del tipo de dato entre paréntesis ya que cuando tengamos que cuando tengamos que declarar los parámetros del PA los vamos a necesitar.
Para esto hacemos un cursor que recorra la tabla y actualice la columna según si tiene decimales o no, pero sólo para aquellas columnas que lo requieran.
DECLARE C_COLUMNAS CURSOR LOCAL FOR
SELECT
orden,
largo,
decimales
FROM
@tabla
WHERE
tipo_dato IN ('VARCHAR','CHAR','NVARCHAR','NCHAR','DECIMAL','NUMERIC')
OPEN C_COLUMNAS
FETCH NEXT FROM C_COLUMNAS INTO
@orden,
@largo,
@decimales
WHILE @@FETCH_STATUS = 0
BEGIN
IF @decimales = 0
UPDATE
@tabla
SET tipo_dato = tipo_dato + '(' + CONVERT(VARCHAR, @largo) + ')'
WHERE
orden = @orden
ELSE
UPDATE
@tabla
SET tipo_dato = tipo_dato + '(' + CONVERT(VARCHAR, @largo) + ',' + CONVERT(VARCHAR,@decimales) + ')'
WHERE
orden = @orden
FETCH NEXT FROM C_COLUMNAS INTO
@orden,
@largo,
@decimales
END
CLOSE C_COLUMNAS
DEALLOCATE C_COLUMNAS
Ahora si, si hiciéramos, otra vez, una consulta sobre @tabla nos quedaría:
orden
columna
pk
parametro
tipo_dato
largo
Decimales
1
Cod_persona
1
@p_Cod_persona
INT
10
0
2
Nombre
0
@p_Nombre
VARCHAR(50)
50
0
3
Apellido
0
@p_Apellido
VARCHAR(50)
50
0
4
Tipo_doc
0
@p_Tipo_doc
SMALLINT
5
0
5
Nro_doc
0
@p_Nro_doc
VARCHAR(20)
20
0
6
Fec_nacimiento
0
@p_Fec_nacimiento
DATETIME
23
3
Una vez recolectado todos los datos y acomodados a nuestro gusto, estamos listos para armar las partes del PA.
LA CABECERA
Siguiendo con el ejemplo de la tabla PERSONAS, la cabecera del PA debería quedar algo asi:
IF EXISTS (SELECT name FROM sysobjects WHERE name = N'PA_ABM_PERSONAS' AND type = 'P')
DROP PROCEDURE PA_ABM_PERSONAS
GO
CREATE PROCEDURE PA_ABM_PERSONAS
(
@p_Cod_persona INT,
@p_Nombre VARCHAR(50)= NULL ,
@p_Apellido VARCHAR(50)= NULL ,
@p_Tipo_doc SMALLINT= NULL ,
@p_Nro_doc VARCHAR(20)= NULL ,
@p_Fec_nacimiento DATETIME= NULL,
@p_accion CHAR(1) --A = ACTUALIZA (INSERT/UPDATE) , E = ELIMINA
)
AS
La primera parte de la cabecera, cómo dijimos al principio, nos servirá para eliminar el PA de la base de datos en caso de que este ya exista, y luego lo volveremos a crear.
Como podemos notar, en la segunda parte, hay columnas que tienen valores por defecto y otras que no. Este se debe, por supuesto, a que las columnas clave tienen que ser obligatorias a la hora de ejecutar las consultas. También vemos que los tipo de dato de texto tienen que ir declarados con su tamaño máximo de caracteres, al igual que los datos decimales.
EL CUERPO
El cuerpo que queremos armar del PA debería quedar asi:
IF (@p_accion = 'A')
BEGIN -- SI LA ACCION ES ACTUALIZAR
IF NOT EXISTS (
SELECT 1
FROM
PERSONAS
WHERE
Cod_persona = @p_Cod_persona
)
INSERT INTO PERSONAS
(
Cod_persona,
Nombre,
Apellido,
Tipo_doc,
Nro_doc,
Fec_nacimiento
)
VALUES
(
@p_Cod_persona,
@p_Nombre,
@p_Apellido,
@p_Tipo_doc,
@p_Nro_doc,
@p_Fec_nacimiento
)
ELSE --SI EXISTE HAGO UPDATE
UPDATE PERSONAS
SET
Nombre = @p_Nombre,
Apellido = @p_Apellido,
Tipo_doc = @p_Tipo_doc,
Nro_doc = @p_Nro_doc,
Fec_nacimiento = @p_Fec_nacimiento
WHERE
Cod_persona = @p_Cod_persona
END --TERMINA DE ACTUALIZAR
ELSE IF @p_accion = 'E'
DELETE PERSONAS
WHERE
Cod_persona = @p_Cod_persona
RETURN @@ROWCOUNT
GO
Para lograr que el script escriba esto en el panel de resultados, debemos usar el método PRINT en cada línea que queramos escribir o en las variables de texto que declaramos al comienzo de esta historia.
ESCRIBIENDO EL PROCEDIMIENTO ALMACENADO EN PANTALLA
Para comenzar a escribir el PA, debemos, en principio, inicializar las variables.
/* INCIALIZO LAS VARIABLES DEL TEXTO */
IF @P_NOMBRE_PA = ''
SET @P_NOMBRE_PA = 'PA_ABM_'+ @P_NOMBRE_TABLA
SET @SQL_WHERE = ' WHERE
'
SET @SQL_INSERT = ' INSERT INTO ' + @P_NOMBRE_TABLA + '
(
'
SET @SQL_VALUES = ' VALUES
(
'
SET @SQL_UPDATE = ' UPDATE ' + @P_NOMBRE_TABLA + '
SET
'
SET @SQL_DELETE = ' DELETE ' + @P_NOMBRE_TABLA + '
'
SET @SQL_CABECERA = 'IF EXISTS (SELECT name FROM sysobjects WHERE name = N''' + @P_NOMBRE_PA + ''' AND type = ''P'')'+CHAR(13) +
'DROP PROCEDURE ' + @P_NOMBRE_PA + CHAR(13) +
'GO' + CHAR(13) + CHAR(13) + + CHAR(13) + CHAR(13) +
'CREATE PROCEDURE '+ @P_NOMBRE_PA + CHAR(13) + '(' + CHAR(13)
La variable @P_NOMBRE_PA la inicializamos con el nombre de la tabla más el prefijo “PA_ABM_”, sólo en caso de que no se haya ingresado un valor al correr el script.
Una vez inicializadas las variables que vamos a utilizar, comenzamos a armar la información que estas van a contener para luego imprimirla en pantalla.
Lo que vamos a hacer es usar un cursor para recorrer la variable @tabla, y vamos a obtener los valores de las columnas “columna”, “parámetro” y “pk”. Además en la variable auxiliar @dato, vamos a armar la declaración de parámetros de la cabecera.
DECLARE C_TABLA CURSOR LOCAL FOR
SELECT
' ' +parametro + ' ' + tipo_dato +
CASE pk
WHEN 0 THEN '= NULL ,'
ELSE ',' END + CHAR(13),
columna,
parametro,
pk
FROM
@tabla
ORDER BY orden
OPEN C_TABLA
FETCH NEXT FROM C_TABLA INTO
@dato,
@columna,
@parametro,
@pk
Por cada registro, si la columna “pk” es igual a 1, es decir, si es clave primaria vamos a armar el WHERE. Caso contrario armamos las columnas a actualizar en la consulta UPDATE. Además, como podemos ver, vamos hacer uso de la bander @update, asignándole el valor 1 para indicar que hay , al menos una columna que no es clave, por lo tanto se tendrá que escribir la cláusula UPDATE.
Luego armamos los valores para las variables @SQL_INSERT y @SQL_VALUES.
Una vez que se terminó de recorrer todo el cursor, lo cerramos y liberamos la memoria.
WHILE @@FETCH_STATUS = 0
BEGIN
-- SI LA COLUMNA ES CLAVE ARMO EL WHERE
IF (@pk = 1)
SET @SQL_WHERE = @SQL_WHERE + ' ' + @columna + ' = ' + @parametro + ' AND ' + CHAR(13)
ELSE IF (@pk = 0)
SELECT @SQL_UPDATE = @SQL_UPDATE + ' ' + @columna + ' = ' + @parametro + ',' + CHAR(13) ,
@update=1
SET @SQL_INSERT = @SQL_INSERT + ' ' + @columna + ',' + CHAR(13)
SET @SQL_VALUES = @SQL_VALUES + ' ' + @parametro +',' + CHAR(13)
set @SQL_CABECERA = @SQL_CABECERA + @dato
FETCH NEXT FROM C_TABLA INTO
@dato,
@columna,
@parametro,
@pk
END
CLOSE C_TABLA
DEALLOCATE C_TABLA
1
2
3
Finalmente, tenemos que limpiar las variables que hemos utilizado, de las impurezas que nos dejó el concatenar los valores de la tabla. Esto depende de la cantidad de espacios y bajadas de línea que se han concatenado.
SET @SQL_WHERE = LEFT(@SQL_WHERE,LEN(@SQL_WHERE) -6)
SET @SQL_INSERT = LEFT(@SQL_INSERT,LEN(@SQL_INSERT)-2) + '
)'
SET @SQL_VALUES = LEFT(@SQL_VALUES,LEN(@SQL_VALUES)-2) + '
)'
SET @SQL_UPDATE = LEFT(@SQL_UPDATE,LEN(@SQL_UPDATE)-2)
IMPRIMIENDO LAS VARIABLES
¡Bueno! Por fin hemos llegado al final del script. Luego de dar tantas vueltas, vamos a ver los resultados, que, por lo menos en mi caso, fueron más que beneficiosos.
Ahora lo único que resta es imprimir las variables en el panel de resultados.
PRINT @SQL_CABECERA + ' @p_accion CHAR(1) --A = ACTUALIZA (INSERT/UPDATE) , E = ELIMINA
)
AS
'
PRINT 'IF (@p_accion = ''A'')'
PRINT 'BEGIN -- SI LA ACCION ES ACTUALIZAR'
PRINT ' IF NOT EXISTS ( '
PRINT ' SELECT 1 '
PRINT ' FROM '
PRINT ' ' + @P_NOMBRE_TABLA
PRINT ' ' + @SQL_WHERE + '
)'
PRINT @SQL_INSERT
PRINT @SQL_VALUES
IF @update=1
BEGIN
PRINT ' ELSE --SI EXISTE HAGO UPDATE
'
PRINT @SQL_UPDATE
PRINT @SQL_WHERE
END
PRINT 'END --TERMINA DE ACTUALIZAR'
PRINT 'ELSE IF @p_accion = ''E''
'
PRINT @SQL_DELETE
PRINT @SQL_WHERE
PRINT '
RETURN @@ROWCOUNT '
PRINT 'GO
'
GO
La disposición de espacios y bajadas de líneas se pueden ir acomodando a lo largo del armado de las variables y de la impresión final.
Una vez que tengamos todo el script escrito en el Analizador de Consultas, resta elegir sobre que base de datos lo vamos a correr, setear la variable @P_NOMBRE_TABLA y correr el script. En el panel de resultados nos va a aparecer todo el texto del PA, lo copiamos y lo pegamos en una nueva consulta y lo corremos.
Espero que les haya servido este artículo. Yo se que a mi me sirvió mucho el script para ahorrar tiempo en escribir este tipo de PA constantemente. Les adjunto el script completo , el cual pueden abrir con el Analizador de Consultas para usarlo.
Agradezco a Franco Raspo, Matias Toro y Andrés Faya, quienes me motivaron y ayudaron para armar este artículo.
Cualquier sugerencia que quieran hacer, modificaciones y/o correcciones (espero que las hagan) las pueden enviar a [email protected].
Sobre las vistas de SQL pueden encontrar más información en:
http://siquelnet.etraducciones.com/default.aspx?Tema=MSSQL&Seccion=SQL&Articulo=005.xml
o en los libros en pantalla de SQL Server 2000.
Hasta la próxima.
Fichero con el código de ejemplo: martinluchessi_Script_generador_codigo_SQL.zip - 2,38 KB